

隐私计算方案落地痛点
作为创新技术,隐私计算在应用落地时面临诸多困难。一般而言,安全性,通用性和性能是隐私计算方案首要考虑的三大要素。
传统隐私计算方案可划分为纯密码学方案和软硬件结合方案,两类方案在通用性以及计算性能上都存在缺陷。具体而言:
- 性能损失:纯密码学方案的计算耗时相比于不用隐私计算的耗时通常增加 100 倍以上,即便是引入硬件加速技术也会降低数倍性能。
- 通用性降低:纯密码学方案通常需要修改算法源码以接入算子库,而硬件方案则需要增加额外的硬件成本,同时分析程序需要改变指令集以及对内存的使用也有限制。
另一个重要的事实是,安全性也并不是一个二元的概念,很多时候根据场景的不同,客户所要求的安全性保证也是可不断变化的,过度追求安全性而忽视性能和通用性就会导致应用落地停滞不前。
可控计算方案
我们从另一角度出发,在满足通用性和性能基础上提供最核心的安全性保证:数据可控可计算,我们称之为可控计算。
考虑一个典型场景:数据以某种安全的方式迁移到在数据使用方的设备上,使用方可以用数据在本地进行任意的计算,不需要修改任何程序源码,同时可以使用 GPU 在内的任何加速设备。但使用方无法将数据或数据执行的结果文件拷出或者其他 I/O 方式获取。
在此场景中,通用性和性能得以保证,并且提供了灵活的安全性约束。根据场景的不同,数据提供方可以选择性的对数据使用方的分析结果文件进行授权,只有经数据提供方授权的文件才能被导出数据使用方的设备,实现数据可用。
DataVault 可控计算
我们提出了一种可控计算解决方案,DataVault。DataVault 被安装在数据使用方的设备上,其保证数据使用方在数据提供方定义的安全域中对数据进行加工、处理。 其中,安全域是一个逻辑上的概念,指由相应密钥和加密算法保护的存储、计算单元。 在多数情况下,安全域由数据提供方定义和约束,但相应的存储、计算资源并不由数据提供方提供。需要注意的是,加工、处理后的中间数据和结果数据也应在相同的安全域中。
安全域不会修改应用。用户在已挂载的安全域中使用数据是对安全域是无感知的,满足了理想场景中的通用性和性能。而安全域中的数据在磁盘等存储设备上是加密存储的,这意味着用户通过物理方式直接从存储设备获取的数据无法使用。通过将Datavault和内存加密技术结合,能够防止用户绕过安全域直接从内存中获取数据,进一步提高安全性。
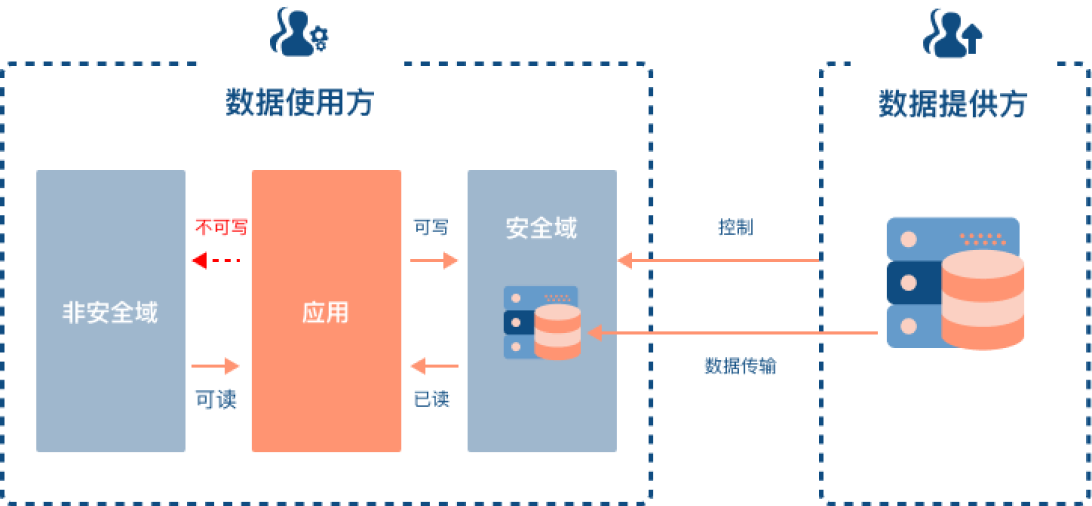
具体而言 DataVault 有如下特性:
- 零侵入性:DataVault 提供了二进制兼容,基于 DataVault 的应用无需修改 代码,这也包括了现有的主流 AI 模型训练框架
- 通用性:DataVault 支持多种 CPU 架构(x86 & ARM)以及基于 PCI-e 的计算设备(GPU、FPGA、各种加速卡等)
- 高性能:相比于不用隐私计算的性能损失不到5%,仅多一次数据加解密的运算
- 安全性:可信基仅为 TPM(Trusted Platform Module,可信赖平台模块)。数据仅能在安全域内使用,文件导出需数据提供方授权。能抵抗窃取内存攻击。
可以发现,DataVault 在 AI 尤其是大模型领域下有广泛的应用场景,由于大模型训练和推理都需要庞大的计算量,传统方案难以实现上述任何场景
- 大模型训练:算力方服务器上安装 DataVault,数据提供方将海量原始导入对应安全域中,算力方执行大模型训练程序后,将训练出的大模型参数导出给数据提供方,保证了原始数据的隐私性。
- 大模型推理:具有模型推理能力的服务器上安装 DataVault,大模型厂商将训练好的大模型参数导入用户安全域中,用户可以使用大模型进行各种推理操作,但无法导出大模型参数,保证了大模型参数的隐私性。
点此了解更多 DataVault 的落地案例。