

大模型困局
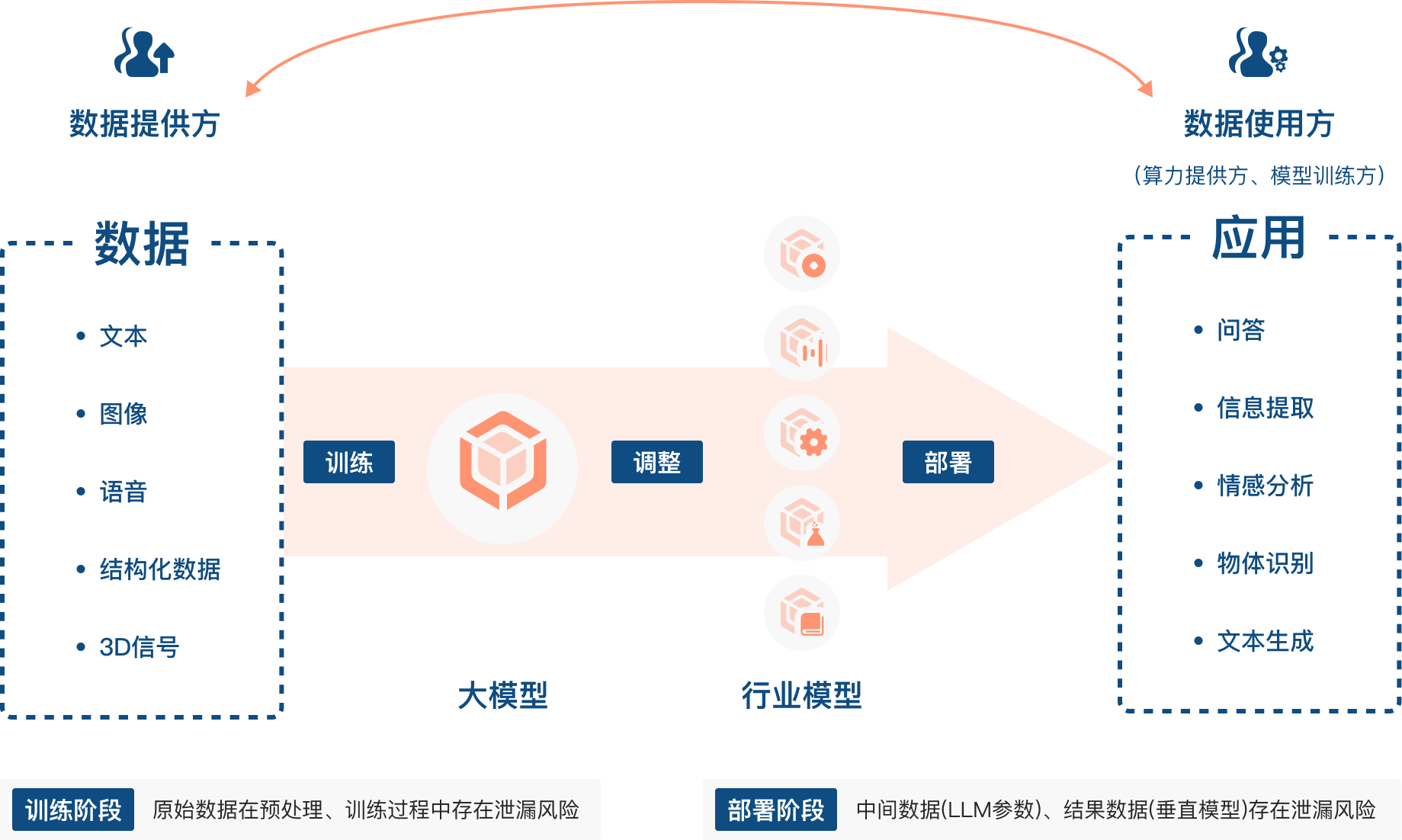
数据,作为决定机器学习模型性能的三大要素之一,正在成为制约 AI 领域发展的瓶颈,模型的质量直接取决于用来训练模型的数据。
随着各种大模型的涌现,数据的重要性进一步凸显,尤其是高质量的数据。然而获取高质量的数据并不容易,研究指出,按照当前大模型吞噬数据的速率,高质量的公域语言数据,例如书籍、新闻报道、科学论文、维基百科等,将在 2026 年左右耗尽。
当大模型发展走向深度,要训练出满足产业需求、精度极高的垂直行业模型,一定需要更多的行业专业知识,甚至商业机密类型的私域数据。但是,出于隐私保护的要求,以及确权、收益划分存在的困难,企业往往不愿意、不能或者不敢分享他们的数据。
可控计算
实际上整个大模型产业的各个环节都需要考虑数据泄露问题,如何使用隐私计算技术来保护 AI 场景下的数据安全,成为了 AI 领域发展过程中的新挑战。
对于目前主流的隐私计算技术,在涉及超大规模数据量的模型训练场景中,尚存在一些问题。
- 以多方安全计算(MPC)、同态加密(HE)为代表的密码学实现技术:相比于使用未加密数据,使用加密数据进行大模型的训练和推理要困难得多;同时,处理加密数据需要更多的计算资源,会指数级地增加处理时间,并进一步加剧训练大模型已经非常高的算力需求。
- 基于可信执行环境(TEE)实现的机密计算技术:目前 TEE 方案主要是基于 CPU 实现的,而大模型训练严重依靠 GPU 算力,但现阶段支持隐私计算的 GPU 方案还不够成熟。
- 融合隐私保护特性的联合建模方案:目前大模型训练通常基于集群实现,分布式训练将会大大增加系统的复杂性,同时还需要考虑模型在各个终端上训练时数据的异质性,以及如何安全地聚合所有设备的学习权重,这些都是目前仍然尚待解决的难题。
此外,也要考虑到引入隐私计算技术之后,对原有的大模型业务产生的影响,包括兼容性问题、性能损失以及部署成本的增加,我们将上述影响称之为隐私计算对原有业务的侵入性。
在此背景下,熠智科技推出了可控计算框架 DataVault,相比于传统的隐私计算技术,DataVault 更强调对于数据计算的可控性,而不是一味追求密文不可见。DataVault 解决了传统隐私计算方案对原有业务的侵入性,非常适合需要处理超大规模数据的大模型训练场景。
算力中心数据安全平台
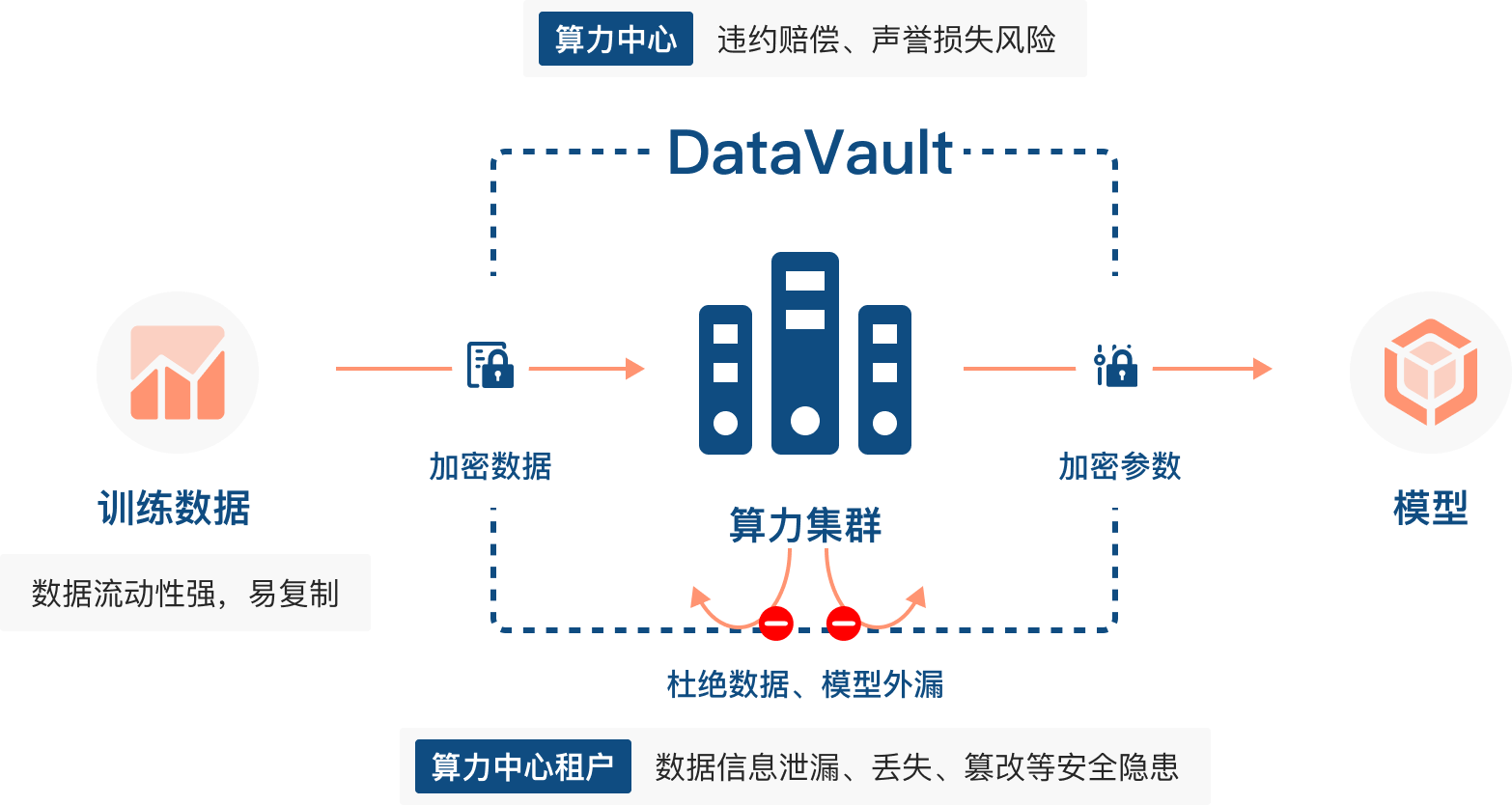
算力是集信息计算力、网络运载力、数据存储力于一体的新型生产力。算力中心作为主要的算力基础设施,可以为高性能计算(HPC)和人工智能(AI)提供大量算力。随着人工智能技术的高速发展,以及大语言模型的出现和应用,各行各业对智能算力的需求也在与日俱增。数据安全能力是算力中心重要的基础保障。在算力中心,通常传输到数据中⼼进行集中式存储,数据在整个过程中存在安全隐患。通过在算力中心部署 DataVault,则可以有效防止算力租户敏感数据泄露。目前 DataVault 已在多个算力中心完成部署。基于 DataVault,数据拥有方可以在集群的存储和计算节点中设定安全域,限制数据的使用范围。
模型推训一体机
除了确保数据在模型训练中的可控,基于 DataVault 解决方案,训练好的大模型本身作为一种数据资产,也可以得到保护并被安全地共享。
目前,对于那些希望在本地部署大模型的企业,例如金融、医疗等高敏感数据机构,苦于缺少在本地运行大模型的基础设施,包括训练大模型的高成本高性能硬件,以及部署大模型后续的运维经验。而对于构建行业大模型的企业,他们则担心如果直接将模型交付给客户,模型本身和模型参数背后积累的行业数据和专业知识存在被二次贩卖的可能。
例如内置 DataVault 的大模型一体机,配备大模型训推所需的基础算力,并内置若干垂直行业模型,可以满足客户开箱即用的需求,同时 DataVault 可以确保这些内置模型仅在获得授权的情况下被使用,模型以及所有中间数据无法被外部环境窃取。