

数据合作中的隐私保护
吃瓜群众可能都听说过一件事儿,去年Facebook深陷欧盟反隐私法案,根据欧盟的《通用数据保护条例》(简称GDPR),Facebook可能要面对数十亿欧元的罚款。排除政治因素,真正让Facebook被欧盟抓住不放的根本原因,其实很简单:欧盟认为Facebook和谷歌这样的企业在“如何收集个人数据以及如何处理这些数据”上面存在问题。
所以我们今天聊一下数据的隐私保护,或者更进一步地,叫数据合作中的隐私保护。
数据合作是什么?
“你有一个苹果,我有一个苹果,彼此交换一下,我们仍然是各有一个苹果;但你有一种思想,我有一种思想,彼此交换,我们就都有了两种思想,甚至更多。” ——萧伯纳
大家今年可能经常听到的“数据生产要素”这个概念,听到生产要素我就头大(毕竟思想政治没学好)。咱们这里就不谈什么是生产要素了,反正我们知道劳动、资本、土地是生产要素,现在数据也成了生产要素。
在面对欧盟反隐私审查时,Facebook副总裁克莱格就曾经说过一句话:“你经常听到数据像石油这句话,正是因为数据不是石油,这不是你从地上吸出来在汽车引擎里燃烧的东西,数据是可以无限分割和无限共享的。”
虽然克莱格这句话有替Facebook甩锅的嫌疑(按照Facebook的逻辑,数据就应该被用来分享),但他确实指出了数据相比苹果或者石油这类传统生产要素的不同。
而最大的不同之处,就是数据具有非常强大的网络效应。尤其是当不同维度不同类别的数据汇合在一起使用的时候,产生的社会和经济价值就会变成1+1>2的效果。而这种多个数据融合使用的过程,我们称之为数据合作。
听起来还是很绕?没关系,先从我们生活息息相关的例子说起。
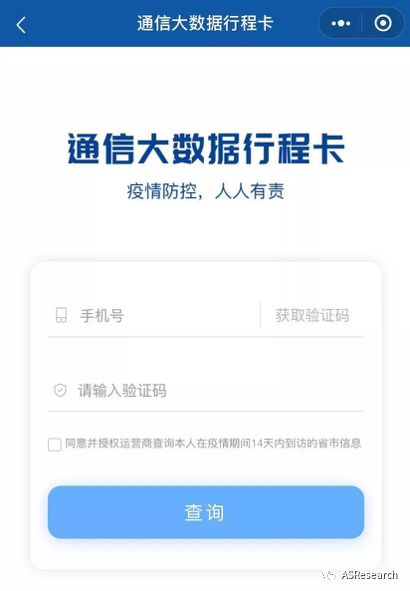
这段时间大家应该都用过这个大数据行程卡,官方介绍是由中国政府网联合工信部和卫健委开发的微信小程序,当我们输入了手机号和验证码就可以查看过去14天自己到过哪些地方,以及自己的健康码级别。
这个行程卡的原理其实很简单,如果你仔细注意“查询”按钮上面的一行小字,就会发现其实这个小程序是根据你手机运营商提供的你的位置信息来进行分析判断的。比如你最近在某些高风险地区停留过,那么手机就会留下位置信息,这些数据是会被三大运营商收集,然后交给信通院进行大数据分析。
实际上这就是一个典型的数据合作场景,这个场景里有两类角色,三大运营商和卫健委是数据提供方是数据提供方:前者提供用户的手机定位信息,后者提供病例数据;而信通院是数据使用方:使用这些数据。通过将运营商的用户定位数据和卫健委统计的病例数据进行联合分析,就能实现对更广范围和更精准的疫情分析和监控,这起到了1+1>2的效果。
回到开头萧伯纳的那句名言,我们把“思想”换成“数据”,会发现同样合适:不同“思想”的碰撞可以产生奇妙的化学反应,而不同的数据融合使用,也可以产生更大的社会和经济效益。
这就是数据合作的意义。
数据合作这个概念近几年来才被提出,但实际上我们生活中已经有着大量数据合作的应用。除了刚才提到的大数据防疫之外,例如我们通过OTA(在线旅游)应用预订酒店的时候,携程或者飞猪(数据使用方)会从酒店(数据提供方)获取相关数据,并且根据用户的历史信息计算最终的订单价格(um,大数据杀熟你懂的)。在普通人感知不到的特定行业领域,数据合作场景更为普遍,比如这几年兴起的供应链金融、综合能源、智慧医疗等等,都需要数据跨域融合使用。
数据合作和隐私保护又有什么关系?
还是以最近的防疫新闻来说。
前段时间突然爆发的XFD疫情让很多人都紧张不已,大家可能有注意到这条新闻。

按道理说通过大数据帮助锁定接触人员名单,应该是值得宣传的好事,为什么支付宝和微信都急于表现出“这锅我不背”的态度呢?
因为支付宝和微信不想像Facebook一样重蹈覆辙。
我们看一下微信的《隐私保护指引》文档里面有这么一句话:
“目前,微信不会主动共享或转让你的个人信息至腾讯集团外的第三方,如存在其他共享或转让你的个人信息或你需要我们将你的个人信息共享或转让至腾讯集团外的第三方情形时,我们会直接征得或确认第三方征得你对上述行为的明示同意”
通俗一点讲,就是tx不会把你的微信数据(个人信息、聊天记录)直接给其他人(当然tx内部是可以使用的),如果给的话也需要征求你的同意。而新发地的大数据溯源在没有通知用户的情况下,腾讯如果提供了用户数据,实际上是违法的。
说到个人数据隐私保护的法律法规,除了欧盟的GDPR之外,我们国家近几年也出台了大量相关法律法规,单就个人隐私保护而言,有《民法典》、《个人信息保护法》 、《刑法修正案七》、《刑法修正案九》、《网络安全法》、《电信和互联网用户个人信息保护规定》、《儿童个人信息网络保护规定》、《数据安全法(草案)》等多个法律法规,例如今年新颁布的《民法典》,就设有“隐私权和个人信息保护”专章内容。可以说,随着民众对个人隐私数据保护意识的逐渐觉醒以及国家法律的完善,企业泄露用户隐私数据的乱象将一定程度上得到治理。
实际上政府企业所拥有的数据除了其收集的用户个人信息外,还包括了自身的财务、生产数据等等,而这些数据也是重要的资产,一旦泄露,也会对政府企业造成严重损失。
因此可以说,隐私保护是数据合作的基石,政府企业的数据隐私无法保护,企业数据合作则只能是纸上谈兵。
那么,我们能否在不泄露数据隐私的情况下,让企业之间能够实现数据互通合作呢?
从“可用不可见”到“可用可信不可见”
传统的解决方法通过对数据进行适当的匿名处理或者引入噪声,来隐藏隐私数据,这类方法随之而来产生的问题是经过处理后的数据可用性下降,同时,目前一些技术(例如机器学习)可以恢复匿名后的数据,这也大大降低了匿名处理的安全性。
最重要的是,不管是加密还是匿名处理后的数据,一旦交付给使用方,提供方就丧失了数据的拥有权,数据二次贩卖就无法避免。令人心痛的是,目前黑市交易仍然是国内数据交易的主流,国内个人信息泄露数达55.3亿条左右,平均每人就有4条相关的个人信息泄露,这些信息最终的命运,是在黑市中反复倒手,直至被榨干价值。
实际上对于很多数据使用方而言,其本身诉求并非原始数据,而是基于数据分 析做出数据驱动决策(data-driven decision-making)。举个例子,在供应链金融场景中,金融机构并不关心供应商实际的物流、销售数据而是需要基于上述数据判断后者是否符合融资或者贷款要求。这为数据合作隐私保护提供了新的解决思路。
近几年随着可信执行环境(TEE)等技术的发展,上述思路得以演变成真正可行的解决方案。这类解决方案的核心思想,是通过将对于数据的使用或者计算进行迁移,数据提供方提供数据处理服务而并非原始数据,数据使用方不接触原始数据,这样就从根本上避免数据出域造成隐私泄露,上述思想通常被称为“数据可用不可见”。
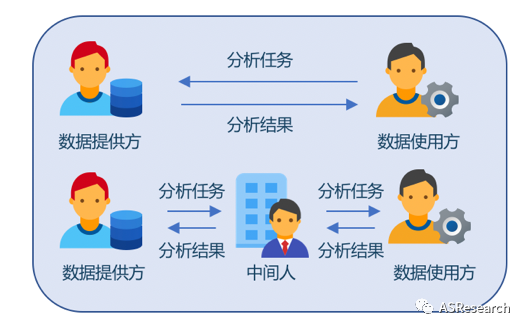
这种模式确实能解决数据泄露的问题。但是随之而来产生了新的信任问题,具体来说是:
1.原始数据的一致性:即如何保证计算过程的输入数据是数据提供方声称提供的数据,且没有被篡改;
2.计算逻辑可控:即如何保证计算结果不包含数据提供方意愿之外的信息,从而造成数据不可见情况下的隐私泄露;
3.计算结果的正确性:即如何保证计算结果是由数据使用方提供的计算程序(且未经篡改)生成的,而不是数据提供方随意生成的;
4.计算结果的隐私性:即如何保证计算结果仅数据使用方可见,数据提供方不能查看计算结果。
这些问题在数据使用方获得原始数据的情况下都是天然保证的,而在“数据可用不可见”的情况下,这些问题的重要性便凸显出来,甚至在一定程度上阻碍了数据合作的可能性。
只有真正解决了上述问题,数据合作的参与方:数据提供方和数据使用方才能互相信任,也才有进行合作的基础。因此可以说,数据合作中的隐私保护不仅仅是“可用不可见”,而更应该是“可用可信不可见”。
如何做到“可用可信不可见”呢?且听下回分解。